Recursive Intelligence: Using LLMs with Emacs
I first used Emacs as a text editor 20 years ago. For over a decade, I have used it daily — for writing and coding, task and finance management, email, as a calculator, and to interact with local and remote hosts. I continue to discover new functionality and techniques, and was suprised to see how this 50-year old program has adapted to the frontier of technology.
This video shows a large language model (LLM), running on my workstation, using Emacs to determine my location, retrieve weather data, and email me the results. By "thinking", the LLM determines how to chain available tools to achieve the desired result.
With karthink's gptel package and some custom code, Emacs is capable of:
- Querying models from hosted providers (Anthropic, OpenAI, OpenRouter), or local models (llama.cpp, ollama).
- Switching between models and configurations with only a few keystrokes.
- Saving conversations to the local filesystem, and using them as context for other conversations.
- Including files, buffers, and terminals as context for queries.
- Searching the web and reading web pages.
- Searching, reading, and sending email.
- Consulting agendas, projects, and tasks.
- Executing Emacs Lisp code and shell commands.
- Generating images via the ComfyUI API.
- Geolocating the device and checking the current date and time.
- Reading man pages.
- Retrieving the user's name and email.
Because LLMs understand and write Emacs Lisp code, they can extend their own capabilities; the improvements are recursive. Below, I note some of the setup required to enable this functionality.
Emacs
With use-package, MELPA, and pass for password management, a minimal configuration for gptel looks like this:
(use-package gptel
:commands (gptel gtpel-send gptel-send-region gptel-send-buffer)
:config
(setq gptel-api-key (password-store-get "open-ai/emacs")
gptel-curl--common-args
'("--disable" "--location" "--silent" "--compressed" "-XPOST" "-D-")
gptel-default-mode 'org-mode)
:ensure t)This is enough to start querying OpenAI's API from Emacs.
To use Anthropic's API:
(gptel-make-anthropic "Anthropic"
:key (password-store-get "anthropic/api/emacs")
:stream t)I prefer OpenRouter, to access models across providers:
(gptel-make-openai "OpenRouter"
:endpoint "/api/v1/chat/completions"
:host "openrouter.ai"
:key (password-store-get "openrouter.ai/keys/emacs")
:models '(anthropic/claude-opus-4.5
anthropic/claude-sonnet-4.5
anthropic/claude-3.5-sonnet
cohere/command-a
deepseek/deepseek-r1-0528
deepseek/deepseek-v3.1-terminus:exacto
google/gemini-3-pro-preview
mistralai/devstral-medium
mistralai/magistral-medium-2506:thinking
moonshotai/kimi-k2-0905:exacto
moonshotai/kimi-k2-thinking
openai/gpt-5.1
openai/gpt-5.1-codex
openai/gpt-5-pro
perplexity/sonar-deep-research
qwen/qwen3-max
qwen/qwen3-vl-235b-a22b-thinking
qwen/qwen3-coder:exacto
z-ai/glm-4.6:exacto)
:stream t)The choice of model depends on the task and its budget. Even where those two parameters are comparable, it is sometimes useful to switch models. One may have a blind spot, where another will have insight.
With gptel, it is easy to switch models mid-conversation, or use the output from one model as context for another. For example, I've used Perplexity's Sonar Deep Research to create briefings, then used another LLM to summarize findings or answer specific questions, augmented with web search.
Tools
Tools augment a model's perception, memory, or capabilities. The gptel-make-tool function allows one to define tools for use by an LLM.
When making tools, one can leverage Emacs' existing functionality. For example, the read_url tool uses url-retrieve-synchronously, while get_user_name and get_user_email read user-full-name and user-mail-address. now, used to retrieve the current date and time, uses format_time_string:
(gptel-make-tool
:name "now"
:category "time"
:function (lambda () (format-time-string "%Y-%m-%d %H:%M:%S %Z"))
:description "Retrieves the current local date, time, and timezone."
:include t)Similarly, if Emacs is configured to send mail, the tool definition is straightforward:
(gptel-make-tool
:name "mail_send"
:category "mail"
:confirm t
:description "Send an email with the user's Emacs mail configuration."
:function
(lambda (to subject body)
(with-temp-buffer
(insert "To: " to "\n"
"From: " user-mail-address "\n"
"Subject: " subject "\n\n"
body)
(sendmail-send-it)))
:args
'((:name "to"
:type string
:description "The recipient's email address.")
(:name "subject"
:type string
:description "The subject of the email.")
(:name "body"
:type string
:description "The body of the email text.")))For more complex functionality, I prefer writing shell scripts, for several reasons:
- The tool definitions are simpler. For example, my
qwen-imagescript includes a largeJSONobject for the ComfyUI flow. I prefer to leave it outside my Emacs configuration. - Tools are accessible to LLMs that may not be running in the Emacs environment (agents, one-off scripts).
- Fluency. LLMs seem better at writing bash (or Python, or Go) than Emacs Lisp, so it easier to lean on this inherent expertise in developing the tools themselves.

M.C. Escher, Drawing Hands (1948)
Web Search
For example, for web search, I initially used the tool described in the gptel wiki:
(defvar brave-search-api-key (password-store-get "search.brave.com/api/emacs")
"API key for accessing the Brave Search API.")
(defun brave-search-query (query)
"Perform a web search using the Brave Search API with the given QUERY."
(let ((url-request-method "GET")
(url-request-extra-headers
`(("X-Subscription-Token" . ,brave-search-api-key)))
(url (format "https://api.search.brave.com/res/v1/web/search?q=%s"
(url-encode-url query))))
(with-current-buffer (url-retrieve-synchronously url)
(goto-char (point-min))
(when (re-search-forward "^$" nil 'move)
(let ((json-object-type 'hash-table))
(json-parse-string
(buffer-substring-no-properties (point) (point-max))))))))
(gptel-make-tool
:name "brave_search"
:category "web"
:function #'brave-search-query
:description "Perform a web search using the Brave Search API"
:args (list '(:name "query"
:type string
:description "The search query string")))However, there are times I want to inspect the search results. I use this script:
#!/usr/bin/env bash
set -euo pipefail
API_URL="https://api.search.brave.com/res/v1/web/search"
check_deps() {
for cmd in curl jq pass; do
command -v "${cmd}" >/dev/null || {
echo "missing: ${cmd}" >&2
exit 1
}
done
}
perform_search() {
local query="${1}"
local res
res=$(curl -s -G \
-H "X-Subscription-Token: $(pass "search.brave.com/api/emacs")" \
-H "Accept: application/json" \
--data-urlencode "q=${query}" \
"${API_URL}")
if echo "${res}" | jq -e . >/dev/null 2>&1; then
echo "${res}"
else
echo "error: failed to retrieve valid JSON res: ${res}" >&2
exit 1
fi
}
main() {
check_deps
if [ $# -eq 0 ]; then
echo "Usage: ${0} " >&2
exit 1
fi
perform_search "${*}"
}
main "${@}"
Which can be called manually from a shell: brave-search 'quine definition' | jq -C | less.
The tool definition condenses to:
(gptel-make-tool
:name "brave_search"
:category "web"
:function
(lambda (query)
(shell-command-to-string
(format "brave-search %s"
(shell-quote-argument query))))
:description "Perform a web search using the Brave Search API"
:args
(list '(:name "query"
:type string
:description "The search query string")))Context
One limitation that I have run into with tools is context overflow — when retrieved data exceeds an LLM's context window.
For example, this tool lets an LLM read man pages, helping it correctly recall command flags:
(gptel-make-tool
:name "man"
:category "documentation"
:function
(lambda (page_name)
(shell-command-to-string
(concat "man --pager cat" page_name)))
:description "Read a Unix manual page."
:args
'((:name "page_name"
:type string
:description
"The name of the man page to read. Can optionally include a section number, for example: '2 read' or 'cat(1)'.")))
It broke when calling the GNU units man page, which exceeds 40,000 tokens on my system. This was unfortunate, since some coversions, like temperature, are unintuitive:
units 'tempC(100)' tempF
With gptel, one fallback is Emacs' built in man functionality. The appropriate region can be selected with -r in the transient menu. In some cases, this is faster than a tool call.
I ran into a similar problem with the read_url tool (also found on gptel wiki). It can break if the response is larger than the context window.
(gptel-make-tool
:name "read_url"
:category "web"
:function
(lambda (url)
(with-current-buffer
(url-retrieve-synchronously url)
(goto-char (point-min)) (forward-paragraph)
(let ((dom (libxml-parse-html-region
(point) (point-max))))
(run-at-time 0 nil #'kill-buffer
(current-buffer))
(with-temp-buffer
(shr-insert-document dom)
(buffer-substring-no-properties
(point-min)
(point-max))))))
:description "Fetch and read the contents of a URL"
:args (list '(:name "url"
:type string
:description "The URL to read")))
When I have run into this problem, the issue was bloated functional content — JavaScript code CSS. If the content is not dynamically generated, one call fallback to Emacs' web browser, eww. The buffer or selected regions can be added as context. A more sophisticated tool could help in these cases. Long term, I hope that LLMs will steer the web back towards readability, either by acting as an aggregator and filter, or as evolutionary pressure in favor of static content.
Security
The run_command tool, also found in the gptel tool collection, enables shell command execution, and requires care. A compromised model could issue malicious commands, or a poorly prepared command could have unintended consequences. gptel's :confirm key can be used to inspect and approve tool calls.
(gptel-make-tool
:name "run_command"
:category "command"
:confirm t
:function
(lambda (command)
(with-temp-message
(format "Executing command: =%s=" command)
(shell-command-to-string command)))
:description
"Execute a shell command; returns the output as a string."
:args
'((:name "command"
:type string
:description "The complete shell command to execute.")))Inspection limits the LLM's ability to operate asynchronously, without human intervention. There are a few solutions to this problem, the easiest being to offer tools with more limited scope.
Presets
With gptel's transient menu, only a few keystrokes are need to add, edit, or remove context, switch the model one wants to query, change the input and output, or edit the system message. Presets accelerate switching between settings, and are defined with gptel-make-preset.
For example, with GPT-OSS 120B (one of OpenAI's open weights models), a system prompt is necessary to minimize the use of tables and excessive text styling. A preset can load the appropriate settings:
(gptel-make-preset 'assistant/gpt
:description "GPT-OSS general assistant."
:backend "llama.cpp"
:model 'gpt
:include-reasoning nil
:system
"You are a large language model queried from Emacs. Your conversation with the user occurs in an org-mode buffer.
- Use org-mode syntax only (no Markdown).
- Use tables ONLY for tabular data with few columns and rows.
- Avoid extended text in table cells. If cells need paragraphs, use a list instead.
- Default to plain paragraphs and simple lists.
- Minimize styling. Use *bold* or /italic/ only where emphasis is essential. Use ~code~ for technical terms.
- If citing facts or resources, output references as org-mode links.
- Use code blocks for calculations or code examples.")
From the transient menu, this preset can be selected with two keystrokes: @ and then a.
Memory
Presets can be used to implement read-only memory for an LLM. This preset uses Qwen3 VL 30B-A3B with a memory.org file automatically included in the context:
(gptel-make-preset 'assistant/qwen
:description "Qwen Emacs assistant."
:backend "llama.cpp"
:model 'qwen3_vl_30b-a3b
:context '("~/memory.org"))
The file can include any information that should always be included as context. One could also grant LLMs the ability to append to memory.org, though I am skeptical that they would do so judiciously.
Local LLMs
Running LLMs on one's own devices offers some advantages over third-party providers:
- Redundancy: they work offline, even if providers are experiencing an outage.
- Privacy: queries and data remain on the device.
- Control: You know exactly which model is running, with what settings, at what quantization.
The main trade-off is intelligence, though for many purposes, the gap is closing fast. Local models excel at summarizing data, language translation, image and PDF extraction, and simple research tasks. I rely on hosted models primarily for complex coding tasks, or when a larger effective context is required.
llama.cpp
llama.cpp makes it easy to run models locally:
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build
cmake --build build --config Release
mv build/bin/llama-server ~/.local/bin/ # Or elsewhere in PATH.
llama-server -hf unsloth/Qwen3-4B-GGUF:q8_0
This will build llama.cpp with support for CPU based inference, move llama-server into ~/.local/bin/, and then download and run Unsloth's Q8 quantization of the Qwen3 4B. The llama.cpp documentation explains how to build for GPUs and other hardware — not much more work than the default build.
llama-server offers a web interface, available at port 8080 by default.
Weights
Part of the art of using LLMs is selecting an appropriate model. Some factors to consider are available hardware, intended use (task, language), and desired pricing (input and output costs). Some models offer specialized capabilities — Gemma3 and Qwen3-VL offer multimodal input, Medgemma specializes in medical knowledge, and Mistral's Devstral focuses on agentic use.
For local use, hardware tends to be the main limiter. One has to fit the model into available memory, and consider the acceptable performance for one's use case. A rough guideline is to use the smallest model or quantization for the required task. Or, from the opposite direction, to look for the largest model that can fit into available memory. The rule of thumb is that a Q8_0 quantization uses about as much memory as there are parameters, so an 8 billion parameter model will use about 8 GB of RAM or VRAM. A Q4_0 quant would use half that — 4 GB — while at 16-bit, 16 GB.
My workstation, laptop, and mobile (llama.cpp can be used from termux) all run different classes of weights. On my mobile device, I have about 12GB of RAM, but background utilization is already around 8GB. So, when necessary, I use 4B models at Q8_0 or less: Gemma3, Qwen3-VL, and Medgemma. If a laptop has 16GB of RAM with 2GB in use, 8B models might run well enough. The workstation, which has a GPU, can run larger models, with longer context, faster. There are other tricks one can use — flash attention, speculative decoding, MoE offloading — to optimize performance across different hardware configurations.
llama-swap
One current limitation of llama.cpp is that unless you load multiple models at once, switching models requires manually starting a new instance of llama-server. To swap models on demand, llama-swap can be used.
llama-swap uses a YAML configuration file, which is well documented. I use something like the following:
logLevel: debug
macros:
"models": "/home/llama-swap/models"
models:
gemma3:
cmd: |
llama-server
--ctx-size 0
--gpu-layers 888
--jinja
--min-p 0.0
--model ${models}/gemma-3-27b-it-ud-q8_k_xl.gguf
--mmproj ${models}/mmproj-gemma3-27b-bf16.gguf
--port ${PORT}
--repeat-penalty 1.0
--temp 1.0
--top-k 64
--top-p 0.95
ttl: 900
name: "gemma3_27b"
gpt:
cmd: |
llama-server
--chat-template-kwargs '{"reasoning_effort": "high"}'
--ctx-size 0
--gpu-layers 888
--jinja
--model ${models}/gpt-oss-120b-f16.gguf
--port ${PORT}
--temp 1.0
--top-k 0
--top-p 1.0
ttl: 900
name: "gpt-oss_120b"
qwen3_vl_30b-a3b:
cmd: |
llama-server
--ctx-size 131072
--gpu-layers 888
--jinja
--min-p 0
--model ${models}/qwen3-vl-30b-a3b-thinking-ud-q8_k_xl.gguf
--mmproj ${models}/mmproj-qwen3-vl-30ba3b-bf16.gguf
--port ${PORT}
--temp 0.6
--top-k 20
--top-p 0.95
ttl: 900
name: "qwen3_vl_30b-a3b-thinking"nginx
Since my workstation has a GPU and can be accessed on the local network or via WireGuard from other devices, I use nginx as a reverse proxy in front of llama-swap, with certificates generated by certbot. For streaming LLM responses, proxy_buffering off; and proxy_cache off; are essential settings.
user http;
worker_processes 1;
worker_cpu_affinity auto;
events {
worker_connections 1024;
}
http {
charset utf-8;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
server_tokens off;
types_hash_max_size 4096;
client_max_body_size 32M;
# MIME
include mime.types;
default_type application/octet-stream;
# logging
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log warn;
include /etc/nginx/conf.d/*.conf;
}Then, for /etc/nginx/conf.d/llama-swap.conf:
server {
listen 80;
server_name llm.dwrz.net;
return 301 https://$server_name$request_uri;
}
server {
listen 443 ssl;
http2 on;
server_name llm.dwrz.net;
ssl_certificate /etc/letsencrypt/live/llm.dwrz.net/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/llm.dwrz.net/privkey.pem;
location / {
proxy_buffering off;
proxy_cache off;
proxy_pass http://localhost:11434;
proxy_read_timeout 3600s;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}Emacs Configuration
llama-server offers an OpenAI API compatible API. gptel can be configured to utilize local models with something like the following:
(gptel-make-openai "llama.cpp"
:stream t
:protocol "http"
:host "localhost"
:models
'((gemma3
:capabilities (media tool json url)
:mime-types ("image/jpeg"
"image/png"
"image/gif"
"image/webp"))
gpt
(medgemma_27b
:capabilities (media tool json url)
:mime-types ("image/jpeg"
"image/png"
"image/gif"
"image/webp"))
(qwen3_vl_30b-a3b
:capabilities (media tool json url)
:mime-types ("image/jpeg"
"image/png"
"image/gif"
"image/webp"))
(qwen3_vl_32b
:capabilities (media tool json url)
:mime-types ("image/jpeg"
"image/png"
"image/gif"
"image/webp"))))Techniques
Having covered the setup and configuration, here are some practical ways I use Emacs with LLMs, demonstrated with examples:
Simple Q&A
With the gptel transient menu, press m to prompt from the minibuffer, and e to output the answer to the echo area, then Enter to input the prompt.
Brief Conversations
For brief multi-turn conversations that require no persistence, gptel can be used in the *scratch* buffer. Context can be added via the transient menu, -b, -f, or -r as necessary. The conversation is not persisted unless the buffer is saved.
Image-to-Text
With multimodal LLMs like Gemma3 and Qwen3-VL, one can extract text and tables from images.
Text-to-Image
My primary use case is to revisit themes from some of my dreams. Here, a local LLM retrieves a URL, reads its contents, and then generates an image with ComfyUI:
The result:

Research
If I know I will need to reference a topic later, I usually start out with an org-mode file. In this case, I tend to use links to construct context, something like this:
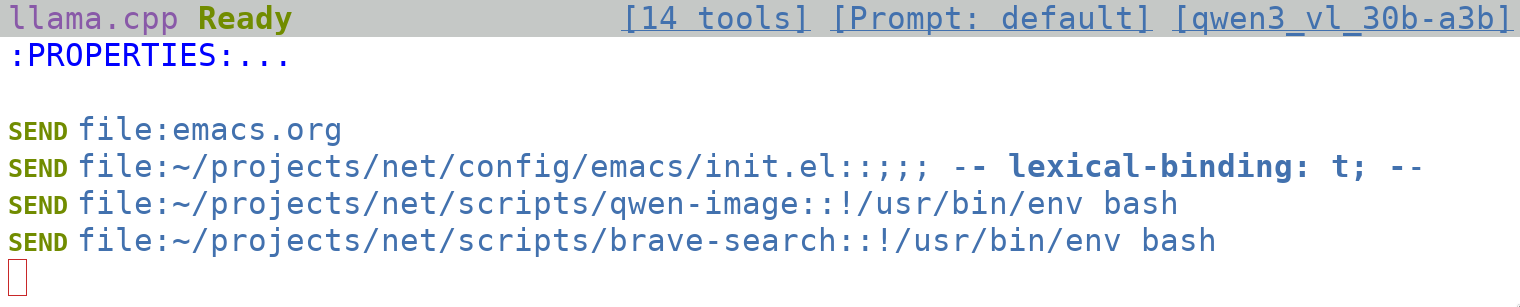
Rewrites
Although I don't use it very often, gptel comes with rewrite functionality, activated when the transient menu is called on a seleted region. It can be used on both text and code, and the output can be diffed, iterated on, accepted, or rejected. Additionally, it can serve as a kind of autocomplete, by having an LLM implement the skeleton of a function or code block.
Translation
For small or unimportant text, Google Translate via the command-line with translate-shell works well enough. Otherwise, I find the translation output from local LLMs is typically more sensitive to context.
Code
My experience using LLMs for code has been mixed. For scripts and small programs, iterating in a single conversation works well. However, with larger codebases, I have not found that LLMs can contribute meaningfully, reliably. This used to be an area of relative strength for hosted models, but I surmise aggressive quantization has begun to reduce their effectiveness.
So far, I have had limited success with agents. My experience has been that they burn through tokens to understand context, but still manage to miss important nuance. This experience has made me hesitant to add tool support for file operations. I am actively exploring some techniques on this front.
For now, I have come to distrust the initial output from any model. Instead, I provide context through org-mode links in project-specific files. I have LLM(s) walk through potential changes, which I review and implement by hand. Generally, this approach saves time, but often, I still work faster on my own.
Reflections
The question of whether a computer can think is no more interesting than the question of whether a submarine can swim.
Edsger Dijkstra
Despite encountering frustrations with LLM use, it is hard to shake the feeling of experiencing a leap in capability. There is something magical to the technology, especially when run locally — the coil whine of the GPU evoking the spirit of Rodin's Thinker. Learning how LLMs work has offered another lens through which to view the world.
My hope is that time will distribute and democratize the technology, in terms of hardware (for local use) and software (system integration). For most users, the barrier to entry for Emacs is high. Other frontends could unlock comparable power and flexibility with support for:
- The ability to assist the user in developing custom tools
- Notebooks featuring executable code blocks
- Links for local and remote content, including other conversations
- Switching models and providers at any point
- Mail and task integration
- Offline operation with local models
- Remote access — Emacs can be accessed via
SSH,gptelfiles viaTRAMP
There are many topics of concern and discussion around LLMs. From my work with them so far, I am more anxious about some than others. Local inference alone reveals how much energy these models can require. On the other hand, the limitations of the technology leave me extremely skeptical of imminent superintelligence. But what we have now, limitations included, is useful — and has potential.